How do you work with data?
Welcome to the latest news from TalkIT. This issue will look at working with data. This follows on from the last newsletter. Technology consumes vast amounts of data. How to optimise data? When to use NoSQL databases? These are just some thoughts, based on 12 years experience training database developers. As usual, I would really like to hear your ideas. Please add your comments at the bottom of the newsletter. Contents Optimise Databases Tables joined to themselves What exactly are NoSQL Databases? Can you solve this coding problem? Other Bits
Contents Optimise Databases Tables joined to themselves What exactly are NoSQL Databases? Can you solve this coding problem? Other Bits
Optimise Relational Databases
Relational Database Management Systems can store and query data. But the performance of large and complex databases tends to degrade overtime. Optimisation is vital. 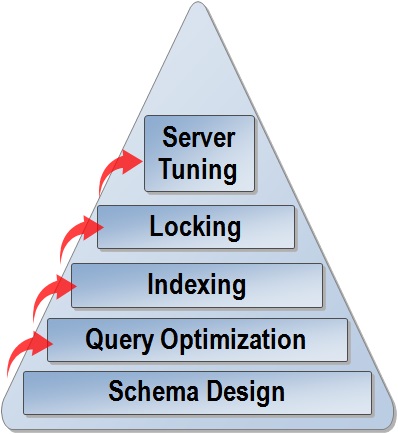 Optimisation can mean many things. We can aim to optimise at server and database level. Probably best to start by defining goals. These can include:
Optimisation can mean many things. We can aim to optimise at server and database level. Probably best to start by defining goals. These can include:
- Improve query response time
- Evaluate user activity
- Monitor security
- Assess ad hoc query impact
Database optimisation starts with good schema design. Store only the relevant data with the appropriate data types. Use the shortest feasible data type. Then normalise the tables to the correct form. Before we attempt to improve performance it is worth evaluating the behaviour of online databases. SQL Server provides several tools to monitor performance. These tools include.
- Execution Plans
- SQL Server Profiler
- system stored procedures and views
- @@ global functions
- Performance and Activity Monitor
Improving query response time is often a major optimisation goal. There is a lot we can do to improve queries, particularly those that join tables. Let’s start by limiting the number of tables in a join. Best to use standard joins rather than sub queries. Also avoid slow cursors. Here is a query that joins to tables. We will use TSQL from a SQL Server database, but this can be easily adapted.
SELECT o.CustomerID, o.OrderID, s.CompanyName as ShipCompany, o.ShipCountryFROM Orders o JOIN Shippers sON o.ShipVia = s.ShipperIDWHERE ShipCountry = 'USA'ORDER BY o.CustomerID, s.CompanyName
SQL server uses its query optimiser to improve query execution. It will select a good join algorithm for a joined query. We can override this by adding our own join hints to the query, but this is rarely a good idea. Query response time can be significantly improved by creating appropriate indexes. Table indexes, just like indexes in a book, make it much quicker to find stuff. But if there are lots of updates, indexes have to be rebuilt frequently to remain efficient. This statement creates an index on the Contact table.
CREATE UNIQUE NONCLUSTERED INDEX ContactON customers (city, companyname, contactname, country, phone)
Here are index recommendations.
- Normalize your database
- Keep clustered index keys narrow
- Re-index regularly with heavy inserts (use auto)
- Avoid too many indexes
- Build indexes to service crucial transactions
- Test with and without to see if plan changes
- Not even an issue unless there’s lots of data
Tables joined to themselves
In the last newsletter we considered table relationships, for example a one-to-many relationship. Now we are going to look at a table that is joined to itself using a self-join. This may sound weird at first, but is a very useful structure. A good example of this is an employees’ table. This can hold each employee’s details, plus who the employee reports to. We can use a table with self joins to hold any hierarchical data. In a one-to-many join the primary and foreign keys are in separate tables. In a self join the primary and foreign keys are in the same table. In fact we can set up as many levels of hierarchy as we need in the same table. So we could keep the whole organisational chart in a single table.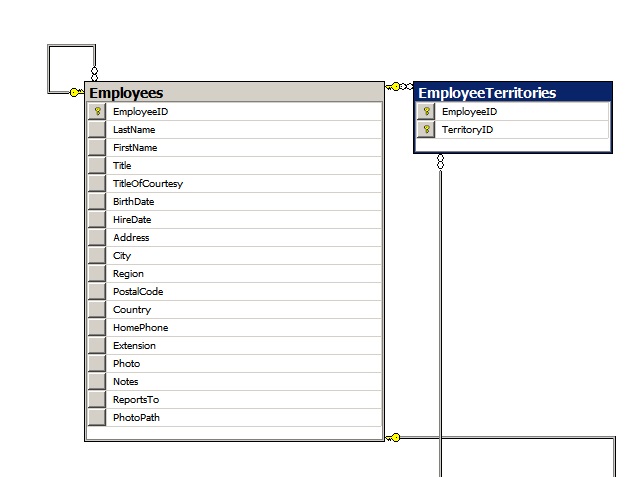 Let’s look at some scripts to work with our Employees table. First create Employees table with Primary Key.
Let’s look at some scripts to work with our Employees table. First create Employees table with Primary Key.
CREATE TABLE [dbo].[Employees]([EmployeeID] [int] IDENTITY(1,1) NOT NULL,[LastName] [nvarchar](20) NOT NULL,[FirstName] [nvarchar](10) NOT NULL,[Title] [nvarchar](30) NULL,…CONSTRAINT [PK_Employees] PRIMARY KEY CLUSTERED
Then add Foreign Key to table.
ALTER TABLE [dbo].[Employees] WITH NOCHECK ADD CONSTRAINT [FK_Employees_Employees] FOREIGN KEY([ReportsTo])REFERENCES [dbo].[Employees] ([EmployeeID])
Finally query the hierarchical data. Here we are asking who reports to the employee with ID of 2.
SELECT EmployeeID, FirstName, LastName, ReportsToFROM dbo.EmployeesWHERE ReportsTo = 2
Take a look at the TalkIT courses and free tutorials in SQL Server. http://talk-it.biz/course-products/sql-server/ http://talk-it.biz/tutorial-categories/sql-server/
What exactly are NoSQL databases?
In the last newsletter we looked at the reasons for using NoSQL databases. We considered the benefits of these compared with relational databases. Here is a comment from the SQLDBA Linked In Group. This points out why NoSQL can be more effective storing non structured data.
 The rise of NoSQL relates more to data structures that don’t line up with the relational model than speed of data access. If someone thinks they can get a generic data set faster from a NoSQL database than a SQL database, they need to find a new database developer (the actual results will vary depending on a few variables, meaning NoSQL or SQL is a non-sequitur).
A good example of the usefulness of NoSQL is a configuration format that constantly changes, but that we need to use on a regular basis (like an XML configuration file for a C# program that changes frequently). NoSQL, without a structured schema, will offer major benefits over constantly adding or removing columns from a SQL database. In the same manner, in the financial world, only so many types of transactions can occur (ie: additions, subtractions), thus most SQL engines will leave NoSQL engines in the dust.
Regardless of what tool a DBA\Developer chooses, they should (1) know their data, and (2) build their storage approach well because no tool will be fast or safe with poor design.
The rise of NoSQL relates more to data structures that don’t line up with the relational model than speed of data access. If someone thinks they can get a generic data set faster from a NoSQL database than a SQL database, they need to find a new database developer (the actual results will vary depending on a few variables, meaning NoSQL or SQL is a non-sequitur).
A good example of the usefulness of NoSQL is a configuration format that constantly changes, but that we need to use on a regular basis (like an XML configuration file for a C# program that changes frequently). NoSQL, without a structured schema, will offer major benefits over constantly adding or removing columns from a SQL database. In the same manner, in the financial world, only so many types of transactions can occur (ie: additions, subtractions), thus most SQL engines will leave NoSQL engines in the dust.
Regardless of what tool a DBA\Developer chooses, they should (1) know their data, and (2) build their storage approach well because no tool will be fast or safe with poor design.
Can you solve this coding problem?
Here is a coding puzzle. The aim is to write a short and elegant program in a language of your choice. This time we are working with a geography quiz. What are the capitals of the 28 EU countries?
- Ask for the capital of a country to entered
- Output if the answer is correct and keep the score
- Generate 10 questions and show the score at the end
- Ask if the quiz wants to be repeated
Try making the program more sophisticated randomly generating the 10 countries. So each time the quiz is repeated the questions will be different. Also some countries are very easy, like France, but others harder. How can the quiz be enhanced to accommodate this? Have a go! This could help you improve your geography!
Other Bits
It was only 2 years ago that Microsoft released SQL server 2012, but this year we have SQL Server 2014. Is it worth upgrading such an important bit of infrastructure? Will any of new features justify this? http://sqlmag.com/sql-server-2014/sql-server-2014-important-new-features TalkIT has created its own e-learning platform to train software developers. This is aimed at anyone who wants to learn a new technology or language from novice to advanced level. You will learn step-by-step how to build business applications and databases. Many of the shorter tutorials are free. We have a launch offer till December only. A subscription to a full length courses cost £4.99. Or you can buy a Gold subscription to all courses for £9.99. To find a tutorial just click: http://talk-it.biz/training/tutorials To find out more look at the FAQ page: http://talk-it.biz/training/tutorials/tutorials-faq/ New online courses in Java, C++, Python courses will be added to the TalkIT site in the next few months. Take an advanced look at what is in the courses: Java http://talk-it.biz/course/training-java-programming-oo-developers/ C++ http://talk-it.biz/course/training-c-programming-oo-developers/ Python http://talk-it.biz/course-products/python/
http://sqlmag.com/sql-server-2014/sql-server-2014-important-new-features TalkIT has created its own e-learning platform to train software developers. This is aimed at anyone who wants to learn a new technology or language from novice to advanced level. You will learn step-by-step how to build business applications and databases. Many of the shorter tutorials are free. We have a launch offer till December only. A subscription to a full length courses cost £4.99. Or you can buy a Gold subscription to all courses for £9.99. To find a tutorial just click: http://talk-it.biz/training/tutorials To find out more look at the FAQ page: http://talk-it.biz/training/tutorials/tutorials-faq/ New online courses in Java, C++, Python courses will be added to the TalkIT site in the next few months. Take an advanced look at what is in the courses: Java http://talk-it.biz/course/training-java-programming-oo-developers/ C++ http://talk-it.biz/course/training-c-programming-oo-developers/ Python http://talk-it.biz/course-products/python/
Photos www.freedigitalphotos.net/
David Ringsell 2014 ©