Recently I have included machine learning in my coding courses. I also found there was a lot of misunderstanding about machine learning. Both of what it is and how it can be practically used. This blog looks at the principles of Machine Learning. If you want to find out more look at our complete training course in Advanced Python Development.

Contents
- Machine Learning Concepts
- Classification of Training Data
- Clustering of Data
1. Machine Learning Concepts
What is exactly is machine learning? Let’s start with a definition.
According to Wiki:
“Machine learning is a field of computer science that uses statistical techniques to give computer systems the ability to “learn” (e.g., progressively improve performance on a specific task) with data, without being explicitly programmed.
Evolved from the study of pattern recognition and computational learning theory in artificial intelligence, machine learning explores the study and construction of algorithms that can learn from and make predictions on data – such algorithms overcome following strictly static program instructions by making data-driven predictions or decisions, through building a model from sample inputs.”
Machine Learning Usage Scenarios
Machine learning is all about building a mathematical model that helps you understand data. Then using this model to make decisions. Many companies sit on huge stores of raw data. They can now use this data to solve business problems.
Example scenarios:
- Email filtering (spam or not-spam)
- Forecasting (e.g., stock market trends)
- Spotting outliers (rogue datapoints)
- Data mining (commercial insights)
- Recommendations (Facebook, Netflix)
There are two categories of machine learning:
- Supervised learning
- Unsupervised learning
What is supervised learning?
You start with known “training data”, which allows you to create a model that describes data relationships. You can then apply the model for “test data”, to predict results and make decisions. Classification is an example of supervised learning. Uses training data to determine how new data should be labelled into existing distinct categories.
Regression is another example. Like classification, except new data is labelled into continuous categories (rather than distinct categories). For example, predicting individual life expectancy based on lifestyle data.
What is unsupervised learning?
With unsupervised data, you don’t start off with any training data. Instead, you try to model the data in its own terms.
Clustering is an example of unsupervised learning. This takes an unlabelled dataset and identifies patterns and trends. It clusters similar inputs into logical groups. Feature reduction is another example. This reduces the number of random variables under investigation, by obtaining a set of principal features. The motivation is to reduce the noise. Data analysis can then be done more accurately.
2. Classification of Training Data
In this section we’ll show a hypothetical example that will help you understand how classification works. Recall, classification is an example of supervised learning.
- You start off with some training data
- You fit a model to the training data
- You can then use the model to classify (predict) future outcomes
Scenario
The following diagram plots 2-dimensional data (i.e., the data contains two features). E.g., feature 1 is a person’s age, feature 2 their academic score. The colour of the dot is an observed label, e.g., how did the person vote in a referendum.
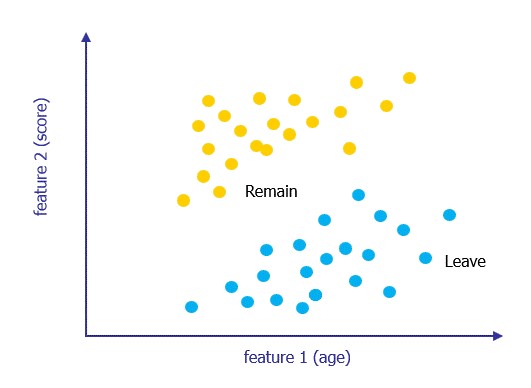 |
The Challenge
Based on the observed training data, here’s the challenge:
How can you predict how other people will vote? i.e., if you measure feature 1 and feature 2 for another person, how can you predict how to label that person (yellow or blue)?
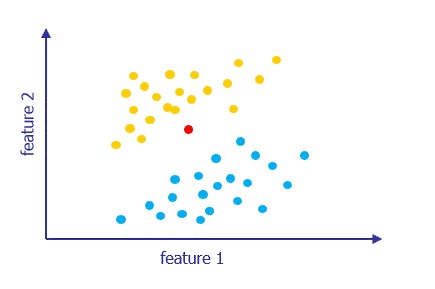 |
Fitting a Model to the Data
There are several ways you can create a model based on this data, and then fit the model to the training data. A simple model would be to assume you can draw a straight line that separates the two categories. To fit the model to the data, just decide where to draw the line.
Using the Model to Label (Classify) Future Results
Based on where you’ve chosen to draw the line. The model predicts that the new data point should be labelled as an yellow dot.
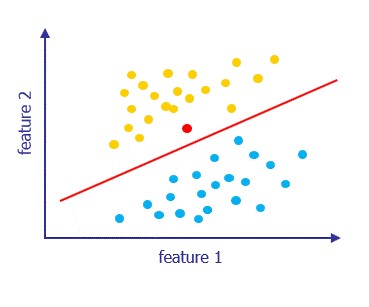 |
Classification in the Real World
The example we just discussed is simple and obvious. We could have just guessed the outcome because the data is so clearly segregated.In the real world, data is much more complicated. There may be thousands or even millions of features (e.g., dubious words in emails). Based on the counts of such words, we could produce a model that labels future emails as spam or not spam.
There are several standard classification models available:
- Naïve Bayes
- Support Vector Machines
Aside: Classification with Continuous Labels
What if you have a continuous label, e.g., life expectancy? How do you classify (predict) new data-points?
One possible approach would be to treat the continuous label as another dimension. Then try to find a model that fits the data. the points. For new data-points, e.g. lifestyle features you can then predict individual life expectancy.
3. Clustering of Data
In this section we’ll show a hypothetical example that will help you understand how clustering works. Recall, clustering is an example of unsupervised learning. You don’t start off with any training data. Instead, you build a model that describes data that doesn’t have any known labels.
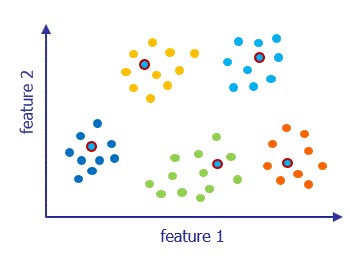
The following diagram plots 2-dimensional data (i.e., the data contains two features). Note that the dots are uncoloured (i.e., the data is unlabelled).
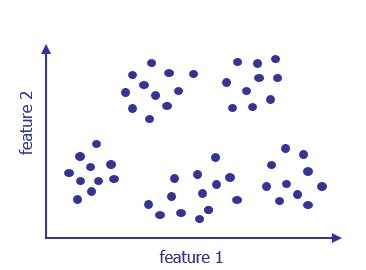 |
Based on this data, here’s the challenge: How can you model the clustering? How can you define discrete groups, and then decide which group a particular data-point belongs to?
There are several clustering algorithms available in machine learning. For example: k-means clustering.
This identifies k cluster centres, by minimising the distance between a cluster centre and the data points in that cluster.
Our example suggests 5 clusters:
 |
After understanding the principles of machine learning, the next stage is to apply them. You can create models from business data, for example. Then use these to gain commercial insights. There are extensive ML libraries in the Python language to help you with this. Have a look at this Advanced Python course outline.
Thanks to Andy Olsen for his excellent course slides
David Ringsell TalkIT 2022 ©